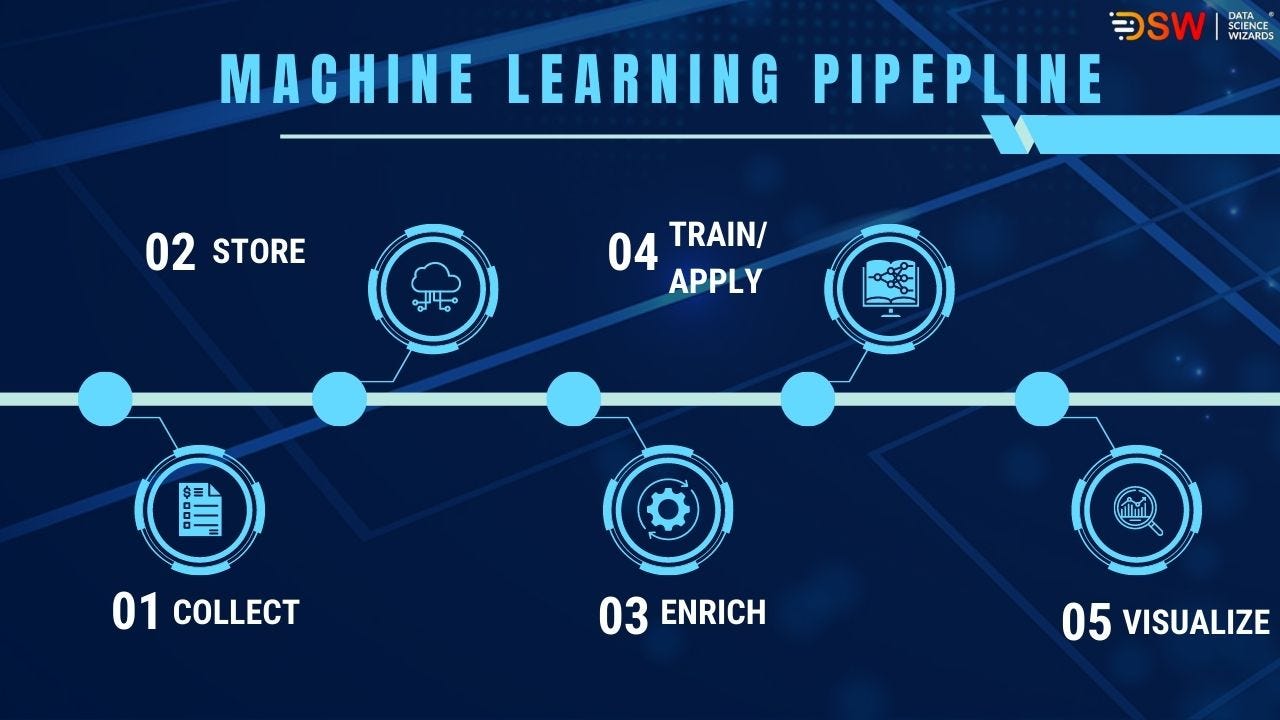
Implementing a machine learning pipeline offers numerous benefits that streamline the development, deployment, and maintenance of machine learning models. Here are the key benefits and how they can positively impact your projects:
1. Improved Workflow Management
- Automation of Repetitive Tasks: Pipelines automate repetitive tasks such as data preprocessing, feature extraction, model training, and evaluation, reducing the likelihood of human error and freeing up time for more complex tasks.
- Standardized Processes: By defining clear steps in the pipeline, it ensures that processes are standardized, leading to more consistent and reliable outputs.
2. Enhanced Collaboration
- Team Coordination: Clear pipeline stages help different team members (data engineers, data scientists, and ML engineers) understand their roles and responsibilities, facilitating better collaboration.
- Version Control: Pipelines integrate with version control systems, making it easier for teams to track changes, manage experiments, and collaborate on model development.
3. Scalability
- Handling Large Datasets: Pipelines can be designed to handle large datasets efficiently, leveraging distributed computing resources when necessary.
- Model Deployment: Automating deployment processes allows for easy scaling of model inference, ensuring that models can handle production workloads effectively.
4. Efficiency and Productivity
- Speeding Up Development: Automated pipelines reduce the time needed for model development and iteration, enabling faster prototyping and deployment.
- Resource Optimization: Efficient use of computational resources is achieved by automating and optimizing various stages of the pipeline, such as using batch processing for large data.
5. Consistency and Reliability
- Reproducible Results: Pipelines ensure that the same steps are followed every time, leading to reproducible results and easier debugging.
- Error Reduction: Automation reduces the risk of manual errors that can occur during data handling and model training processes.
6. Monitoring and Maintenance
- Continuous Monitoring: Pipelines can include stages for monitoring model performance and data quality in production, ensuring that models remain accurate and reliable over time.
- Automated Alerts: Automated systems can alert engineers to any issues, such as model drift or data anomalies, allowing for quicker responses and maintenance.
7. Experimentation and Optimization
- Experiment Tracking: Pipelines can be integrated with experiment tracking tools to record and compare different model configurations and hyperparameters.
- Hyperparameter Tuning: Automated hyperparameter tuning can be included in the pipeline, enabling efficient search and optimization of model parameters.
8. Integration and Deployment
- Seamless Integration: Pipelines facilitate the integration of machine learning models with other systems, such as data warehouses, APIs, and user interfaces.
- Continuous Deployment: Continuous integration and deployment (CI/CD) practices can be implemented in machine learning pipelines to ensure that updates are deployed seamlessly and without disruption.
9. Compliance and Documentation
- Audit Trails: Pipelines can log all operations and changes, creating an audit trail that is essential for compliance and regulatory requirements.
- Comprehensive Documentation: Automated documentation generation can be included in the pipeline, ensuring that all steps and processes are well-documented and easily accessible.
Conclusion
A machine learning pipeline is an essential tool for modern ML projects, providing benefits that enhance workflow efficiency, collaboration, scalability, and overall model reliability. By leveraging pipelines, organizations can streamline their ML processes, from data ingestion to model deployment and monitoring, ultimately leading to more robust and maintainable machine learning systems.


